2022年底,OpenAI用chatGPT再度点燃了人工智能的狼烟,一场名为大模型的竞赛瞬间席卷了全球。
但到了今天,大家讨论最多的不再是规模、算力。即便当下AGI已经成为了一种共识,行业大佬们言之凿凿:AGI很有可能在5年内成为现实,但随着大模型混战进入下半场,无论是投资人还是大厂,更关心的是如何率先让大模型商业化成为可能。
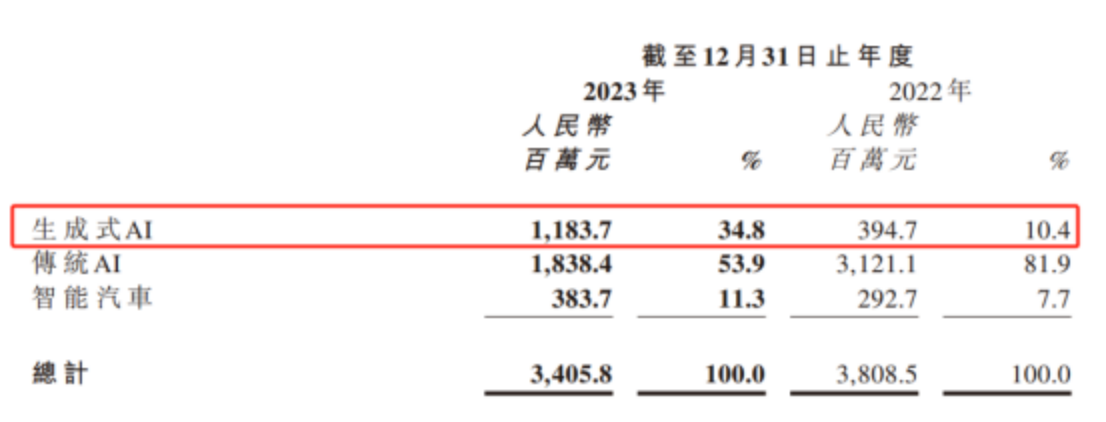
3月26日,商汤集团(下简称“商汤”)发布截至 12 月 31 日的 2023 财年业绩报告。其中一个值得注意的地方是,2023 年,商汤生成式 AI 业务收入达 12 亿元。这也是商汤成立十年以来,最快达到10亿收入体量的新业务。
作为此前国内最炙手可热的AI公司,商汤在生成式 AI 业务上的进展,不仅仅意味着其本身正在走入新时代,对于正在寻求商业化的同行们来说,或许也能提供一些借鉴意义:
商汤是怎么做到的?
商业化闭环
和2022年相比,2023年商汤生成式 AI 业务的收入爆发式增长200%,整体占比也从10% 增长到 35%。
这得益于商汤对于生成式AI的战略重视。
2023年,商汤把自身业务明确划分为生成式 AI、传统 AI 和智能汽车,而此前的智慧城市、智慧商业和智慧生活中的非生成式AI业务,则被并入到传统AI业务内。商汤的愿景和战略目标也转变为“将 AGI 作为核心战略目标,以期在未来几年内实现 AGI 技术的重大突破”。
这么做的原因是,生成式 AI 业务需要足够聚焦的投入。在Scaling Law(尺度定律)的指引下,大量的投入是最基础的事情。根据纽约时报援引对OpenAI创始人山姆.奥特曼的采访,ChatGPT每天要消耗的电量就高达50万度。
OpenAI发布chatGPT后,商汤是反应最迅速最持续的厂商之一。去年4月10日,商汤正式公布“日日新 SenseNova”大模型体系。到今年2月,日日新大模型已经迭代了四个版本,来到了日日新 V4.0。据报道,日日新 V4.0在代码编写、数据分析、医疗问答等多个场景中达到与 GPT-4 相匹配的能力。
如果说对于大模型的持续投入是基础,那么对于现实需求的准确判断则是商汤生成式 AI 业务迅猛发展的点金手。
目前包括手机、电脑、社交、医疗、金融等在内的多个领域,AI都是行业发展和竞争的重要比拼维度。比如智能手机行业,一个能够听取用户的指令,并调用手机上的各类应用程序完成复杂任务的智能终端模型已经被放到了重要卖点。
但由于训练通用大模型的成本太高,更多的厂商们更倾向于通过直接调取API的方式来获得生成式AI的能力。
商汤新的「模型即服务」(MaaS)的商业模式正好适配这股暴涨的需求。通过在大装置微调和调用各类生成式 AI 能力,客户不需要自己去搭建基础设施,大大降低了成本。
一般来说,场景有三个:一是公有云标准,调用 API;二是私有云,对于安全需求客户提供专属模型和模型授权服务;三是模型定制服务。
比如包括招商银行、中国银行等在内的多家知名银行已经采用日日新大模型去构建数字客服系统;郑州大学第一附属医院、上海交通大学医学院附属新华医院、上海交通大学医学院附属瑞金医院等,选择运用“大医”赋能用药咨询、患者随访、临床辅助决策等众多医院真实业务场景。
财报提到,在企业端,生成式 AI 业务中超过 70% 的客户是商汤在过去一年内的新增客户,而剩下 30% 的存量客户的客单价也录得了约 50% 的增速。在C端,日日新大模型赋能 C 端的调用量更是在半年内增长近120倍。
生成式 AI 业务的发展也推动了传统AI业务和智能汽车业务的变革。以智能汽车业务为例,作为AI技术和传统制造结合的最大落地场景,大模型的影响力也在持续。随着特斯拉在美国推送智能驾驶软件FSD v12 Beta版,基于大模型架构的端到端技术方案成为了下一代自动驾驶的最优解。
得益于自家大模型的基础能力,商汤的“绝影”智能汽车业务迎来了迅速增长:量产交付同比大幅增长163%,营收同比增长31%。
不过无论是大模型能力的训练,还是端侧大模型的部署,都是一个长期且困难的事,商汤大举投入的底气在哪?
AI2.0的赛点
在科技行业的语境里,AI并不是一个新词。
以2017年Transformer算法的诞生为分界线,AI被划分为两个时期。前者多聚焦于参数量较小的小模型,针对特定场景获得特定能力,后者则更通用,更基础。
但这并不意味着,过去企业在AI1.0时代的积累和经验,无法在AI2.0时代发挥作用。恰恰相反,商汤过去在感知智能、决策智能等方面的积累,是其生成式AI业务得以快速发展的关键之一。
一方面,AI1.0时代,商汤不仅在计算机视觉方面积累了大量算法模型,覆盖从视觉信号的分析理解到实现数字内容的生成等各方面;也自研并具备了包括语音识别(ASR)、语义理解(NLP/ 知识图谱)、语音合成(TTS)以及语音动画合成(STA)等多项技术能力。这些都能有效强化其基础模型对物理世界的理解和多模态能力。
比如在智能终端领域,得益于商汤在小模型上的积累,同样是7B模型,商汤的性能领先于Meta的Llama2和谷歌的Gemma。2023年,高通、MTK在发布会上展示了商汤子公司慧鲤生成式AI端侧模型在其旗舰芯片上的应用成果:商汤的7B级小型模型在高通最新款芯片上,实现了业界领先的16tokens/秒的推理速度。
另一方面,在大力发展生成式AI业务之前,商汤的AI能力就赋能了不少垂直行业:包括智慧城市、智慧商业、智能汽车和智慧生活等在内的四大板块,涉及了20多个落地场景,其中不乏我们熟悉的手机、金融、医疗等。这让商汤更能洞察当下各行各业对于生成式AI的需求到底在何处,如何针对需求去做供给。
更重要的是,过去商汤在基础设施上的前瞻布局,正在发挥巨大作用。
如果说工业革命时代的基础设施是电力、铁路、运河、港口,那么大模型时代的基础设施则是以GPU为代表的算力。OpenAI首席执行官奥特曼曾表示,“算力是这个时代最重要的货币”。这既关乎成本,也关乎效率。
早在2018年,商汤就着手自建算力中心,并在此基础上打造了SenseCore AI大装置。2022年,商汤在上海临港的智算中心AIDC正式运营,是亚洲最大的人工智能计算中心之一,并在2023年扩展了上海、深圳、广州、福州、济南、重庆等新的计算节点。
业绩公告显示,商汤大装置总算力达到12000petaFLOPS,相较于2023年初提高了一倍,GPU数量达到45000卡,实现了万卡万参的大模型训练能力。
算力只是商汤大装置的计算基础设施,在此之上还包括模型层、深度学习层两个架构,分别对应算法模型生成和算法模型训练。
为了提高算力的供给效率,商汤联合开发了DeepLink开放计算体系。基于此,各类国产芯片可以轻松适配主流的大模型训练框架和算法库。今年,商汤还增加了对华为昇腾、寒武纪等主流国产芯片的适配,支持大模型的训练、微调和推理服务,从而通过提供规模化、高效率、集约化的算力基础设施服务,大幅提高算力的利用能力。

简单来说,就是降本增效。
根据报道,目前商汤大装置在大模型训练服务上可以保持90%的加速效率,提供30天稳定训练不间断的服务,并将出现训练间断时的诊断恢复时长也优化到了半小时。
同时,商汤大装置还支持20个亿参数量超大模型(以千卡并行)并行训练,并新增了对多模态模型和混合专家模型的支持。
这也是为什么商汤可以顶住压力,成为少数可以高速迭代大模型的企业之一。自 2023 年发布以来,商汤“日日新”大模型的能力每隔三个月都会有显著提升。根据弗若斯特沙利文发布的《AI大模型市场研究报告(2023)》,商汤的AI大模型在产品技术、战略愿景、生态开放构建等综合竞争力,在2023年位列国内第一。
共创的未来
IDC最新发布的2024年V1版《全球人工智能和生成式人工智能支出指南》显示,无论是投资规模还是市场规模,AI行业都处于高速增长当中。
2022年全球人工智能(AI)的IT总投资规模为1324.9亿美元。预计到2027年,这一数字将增至5124.2亿美元,年复合增长率为31.1%。特别是生成式AI技术,预计到2027年将占据33.0%的中国AI市场投资份额。
IDC还特别提及了生成式AI市场的年复合增长率可能达到85.7%,到2027年,全球生成式AI市场规模将接近1500亿美元。
但正如红杉中国去年发布的一篇文章所预测,当下AI浪潮的重心是如何利用新技术端到端地解决现实社会中的问题:模型能力和商业化路径本就是一体两面的关系。这既有赖于共创,也需要自身的努力。
这恰是商汤潜力的体现。
根据财报,商汤大装置的降本增效能力已赋能多个领域头部企业机构,其中既包括小米、阅文等行业“灯塔”,也有上海交大等顶尖机构。
“大装置+大模型”的深度协同优势也让商汤可以在保持技术优势的同时,把技术赋能到其他行业。根据官方透露,商汤将于今年4月的技术交流日上,推出“日日新”大模型5.0版本,预期其多模态能力将对标GPT4V。
简单来说,当下商汤既是“电”的提供人,也是“铁路”的铺设者。
正如商汤董事长兼 CEO 徐立所言,“生成式 AI 对商汤来说已不仅仅是技术领域的变革性创新,更成为公司的核心业务。商汤生成式 AI 业务的增长,得益于各行各业对大模型的训练和推理的广泛需求,这预示着中国硬科技投资的新周期正式开启。商汤通过在各业务层面深入融合生成式 AI 能力,正在赢得新客户,并推动效率和生产力的全面提升。”
商汤唯一需要做的,就是把当下的路坚持下去。