AI大模型:开启智能新纪元

核心观点:
为突破Transformer算法结构计算复杂度高、训练推理成本高昂、多模态处理能力不足等局限,近年来MoE、多模态模型、Diffusion模型等算法架构得以重视,剪枝、稀疏、蒸馏等推理优化技术应运而生。
目前,AI Agent正成为大模型应用热点方向之一,用于智能体之间通信协作的协议,比如MCP、A2A,逐渐兴起。
2024年全球大模型融资超1,800亿人民币,60%资金流向应用层;应用落地呈现“微笑曲线”,多模态成主流方向。金融、医疗渗透率超50%,同时应用集中于高附加值环节,如研发设计+营销服务。
全球范围内,2024年大模型市场规模超280亿美元,未来五年复合增速或达到36.23%,2028年有望超过1,000亿美元。
中美模型性能差从2024年1月的9.26%缩至2025年2月的1.70%,国产模型如DeepSeek-V3以1/8成本逼近GPT-4o。
国内形成“互联网巨头+创业六小强”格局,百度文心、阿里通义深耕中文场景,智谱GLM、DeepSeek开源模型下载量超2亿次,推动AI平权。
行业概述
(1)定义
人工智能(AI)大模型指利用深度学习算法让计算机从复杂数据集中自动提取关键特征并做出精准决策的具有超大参数规模的模型。
(2)特征
AI大模型具有泛化性(知识迁移到新领域)、通用性(不局限于特定领域)以及涌现性(产生预料之外的新能力)三大特征。
(3)类型
从应用范围划分,大模型主要分为通用大模型和行业大模型;从开放程度划分,大模型主要分为闭源和开源;从模态类型划分,大模型主要分为单模态、多模态、跨模态等。
图1:中文大模型类型划分
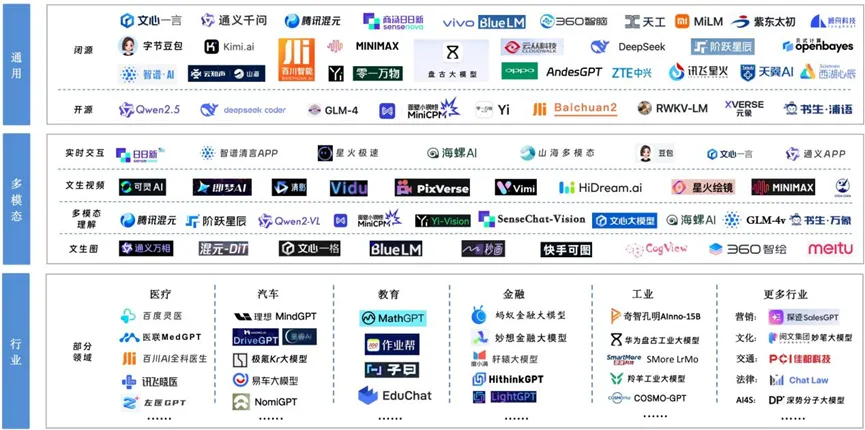
来源:融中咨询
(4) “智力”来源
大模型的智力是数据、算法、算力、训练方法共同作用的产物,其核心机制可归纳为四个:Transformer算法、Scaling Law、涌现能力、预训练和微调。
Transformer算法:当前主流大模型普遍是基于Transformer算法进行设计的。Transformer的核心优势在于具有独特的自注意力(Self-attention)机制,能够直接建模任意距离的词元之间的交互关系,解决了循环神经网络(RNN)、卷积神经网络(CNN)等传统神经网络存在的长序列依赖问题。
Scaling Law:它描述了模型性能与规模因素之间的幂级关系。在一定范围内,如果增加参数量、训练数据量或计算量,那么模型的损失(例如困惑度 Perplexity)会按幂律下降,性能线性或超线性提升。换句话说,“越大越聪明”。
涌现能力:随着模型参数规模、数据量等达到某个临界点,模型突然表现出小模型无法实现的新能力,这些能力不是逐渐出现的,而是非线性地“跃迁”出来的,即模型在理解和解决复杂任务时发生质变,展现出类似人类智能的推理、泛化和创造能力。
预训练和微调:大模型通常采用预训练和微调的策略。预训练阶段,模型在大量无标注数据上进行自监督学习,掌握语言的通用表示;微调是在预训练基础上,用特定任务或特定格式的数据对模型再训练,以获得更专用、更准确的能力,以适应具体任务需求。
(5)典型创新技术
为突破Transformer算法结构计算复杂度高、训练推理成本高昂、多模态处理能力不足等局限,近年来MoE、多模态模型、Diffusion模型等算法架构得以重视,剪枝、稀疏、蒸馏等推理优化技术应运而生。
1)算法架构
MoE(专家混合模型):通过引入“稀疏激活”的专家模块,在每次向前推理时只激活部分专家网络,解决了“大模型 = 高推理开销”的难题;
多模态模型:引入图像、音频、视频等感知能力,在一个模型中融合处理多种模态信息,实现“看图说话”、“读图写代码”、“音视频理解”等能力;
Diffusion(扩散)模型:强调可同时生成多个Token,并能于生成过程中持续修正内容,如Google Gemini Diffusion在部分文字生成任务的运算速度有着明显提升,官方资料最高平均达每秒1,479 Token,明显高于Gemini 2.0 Flash-Lite等传统模型。
2)推理优化
剪枝:在训练后去除对输出影响小的参数或连接,例如低权重神经元、通道或注意力头,减少了模型体积与计算需求。
稀疏:只激活部分神经元/专家节点,而非全部参数参与运算(如MoE架构)。在大参数量模型中实现计算量线性缩放,显著降低推理成本。
蒸馏:用一个大模型(教师模型)的输出结果训练一个小模型(学生模型),让小模型学习大模型的“软目标”分布。蒸馏大幅减少参数与计算量,同时保持接近的准确度。
发展历程及趋势
1)发展简史
自从20世纪50年代图灵测试被提出以来,人类一直在探索如何用机器掌握语言智能。作为一种主要的语言理解和生成方法,自然语言处理模型(Natural Language Processing,NLP)在过去的二十年中得到了广泛的研究,并从统计语言模型逐步发展为神经语言模型。从2022年开始,大模型行业呈现爆发式增长。
图2:语言大模型发展历史及代表性里程碑事件
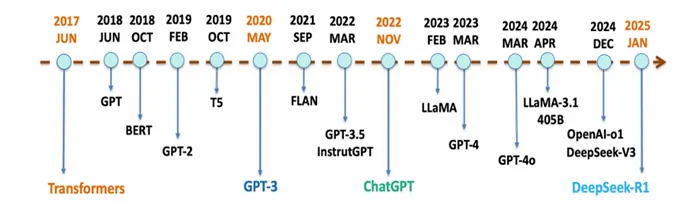
来源:DeepSeek技术社区
Transformer的引入(2017年):2017年,Vaswani等人通过其论文“Attention is All You Need”引入了Transformer架构,解决了早期模型如循环神经网络(RNNs)和长短期记忆网络(LSTMs)的关键限制,为现代大型语言模型奠定了基础。
推进式对话AI——ChatGPT(2022年):2022年3月,OpenAI推出了GPT-3.5,相比于GPT-3,训练和微调有所改进。基于GPT-3.5和InstructGPT,OpenAI于2022年11月推出了对话式AI模型——ChatGPT,大模型开始向C端用户普及。
多模态模型的问世(2023年):2023-2024年,像GPT-4V和GPT-4o这样的多模态大型语言模型,实现了将文本、图像、音频和视频整合到统一系统中。这些模型扩展了传统语言模型的能力边界,实现了更丰富的交互手段和解决更复杂问题的能力。
推理模型快速发展(2024年):2024年9月,OpenAI发布的o1-preview大模型标志着人工智能的一次进步,尤其是在解决复杂推理任务(如数学和编程)方面。2025年1月,OpenAI发布o3,它在编程、数学、知识问答等领域都打破了o1创造的纪录。
2)未来趋势:行业应用与AI智能体
目前,AI Agent(人工智能自主智能体)正成为大模型应用热点方向之一。它是一种能够独立思考、感知环境、进行决策和执行动作的智能实体,其底层架构逻辑可以概括为:“大模型+插件+执行流程/思维链”。
随着多智能体协作场景的日益重要和复杂,用于智能体之间通信协作的协议,比如MCP、A2A,逐渐兴起。
政策与融资动态
(1)政策环境
在国家层面,政府陆续发布了支持大模型行业技术研发、标准化体系建设和数据要素开发等层面的政策方针,旨在推动大模型在工业、医疗等领域的应用。政策总体注重安全合规与技术创新的平衡,引导产学研协同发展。
表1:中国AI大模型行业相关扶持政策
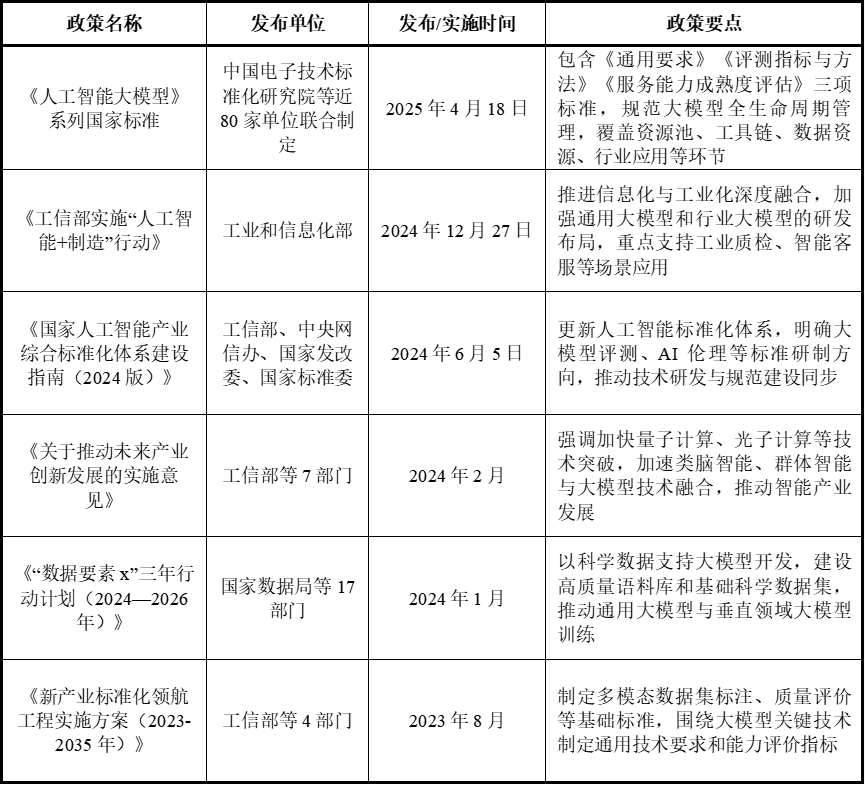
来源:融中咨询
(2)融资动态
1)全球
基于《2024年大模型融资全景》数据,2024年下半年全球大模型产业链上下游共94起融资事件,总融资额超1,800亿人民币。其中关于各类大模型研发厂商的融资事件共84起,其余事件主要为产业链上游基础设施和安全系统提供商。
图3:2024H2各类大模型企业融资数量占比
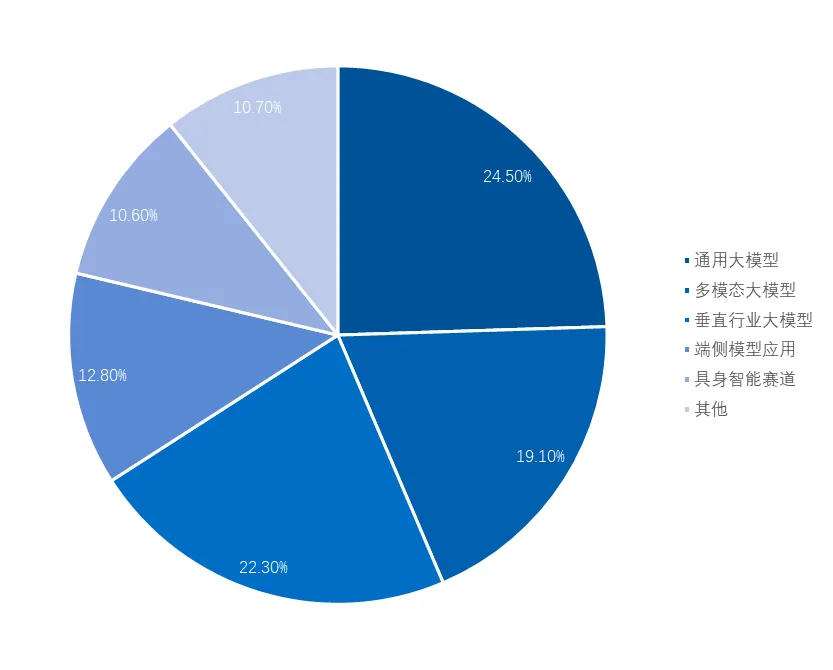
来源:融中数据
2)中国
2020-2022年,国内大模型投融资事件数量未超过5起,总额均不超15亿。2023年有20起,投融资金额为64.27亿元。
到了2024年,全面爆发,全年共118起融资事件,总额超620亿元。
2025年Q1人工智能领域合计发生融资案例241起(不含未公开事件),合计涉及融资金额181.4亿元(仅统计已披露的融资金额)。
图4:2020-2025Q1大模型行业投融资事件数量、金额变化情况
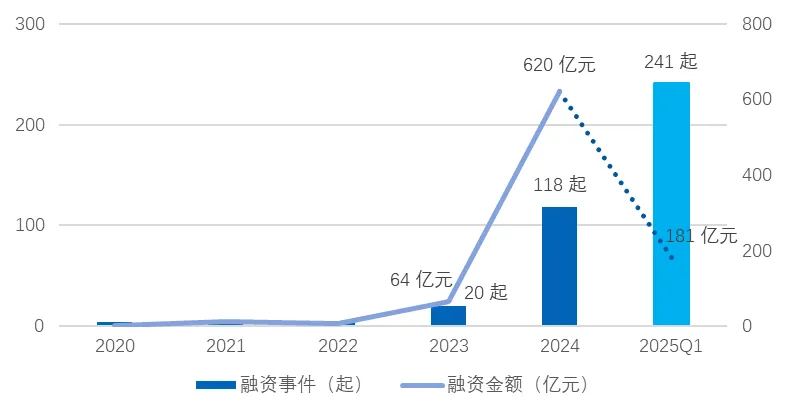
来源:融中数据
分区域来看,北京、广东、上海、浙江、江苏等地的融资案例数和金额排名靠前。2025年Q1融资案例数前五的地域是北京、广东、上海、浙江和江苏,合计205起,占比85.1%;融资金额方面,2025年Q1融资金额前五的地域是北京、上海、广东、浙江和江苏,合计168.5亿元,占比92.9%。
图5:2025Q1国内大模型融资地区金额分布
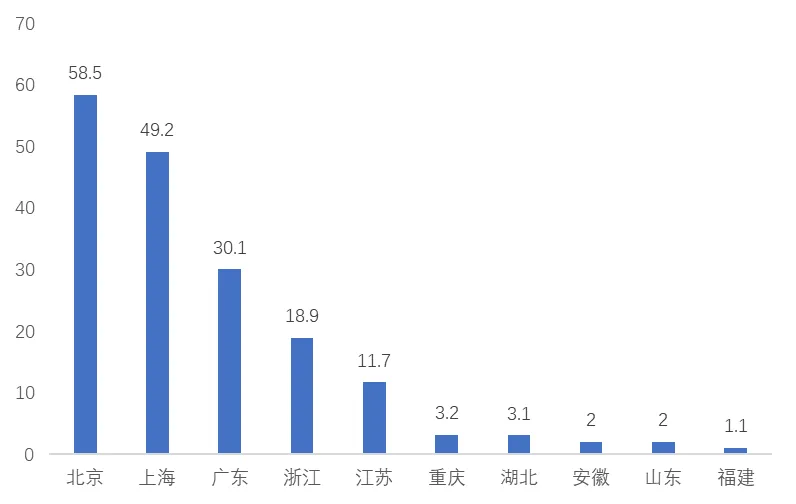
来源:融中数据
从融资阶段来看,国内AI大模型企业仍以早期为主。早期融资案例(种子轮至A轮)占比由2024年Q4的67.0%小幅上升至2025年Q1的67.2%,早期融资金额占比由2024年Q4的31.6%上升至2025年Q1的45.1%。中后期(B轮至Pre-IPO轮)融资金额占比由2024年Q4的50.4%下降至2025年Q1的40.2%,战略融资的融资金额占比由2024年Q4的17.9%下降至2025年Q1的14.8%。
图6:2025年第一季度国内融资金额对应轮次占比
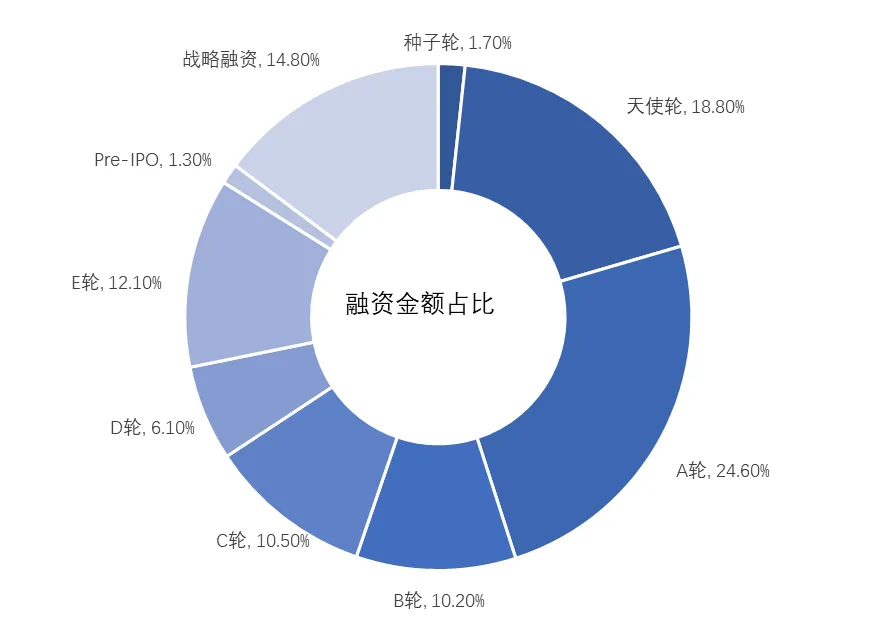
来源:融中数据
行业全景与市场规模
(1)产业链结构与角色分布
大模型产业链是一个涵盖硬件基础设施、数据与算法服务、模型研发及行业应用的多层次生态体系。
上游:主要由算力设施、数据服务商和算法供应商构成,为模型训练提供计算资源与数据基础。
中游:聚焦于大模型的研发与优化,包括通用大模型和垂直行业大模型的开发,企业通过深度学习框架进行预训练与微调,形成文本、图像、多模态等生成能力。
下游:是产业链的核心,渗透至医疗、教育、政务、工业等千行百业,通过行业大模型解决特定场景问题,如智能客服、辅助诊断、生产优化等。
图7:大模型产业链图谱
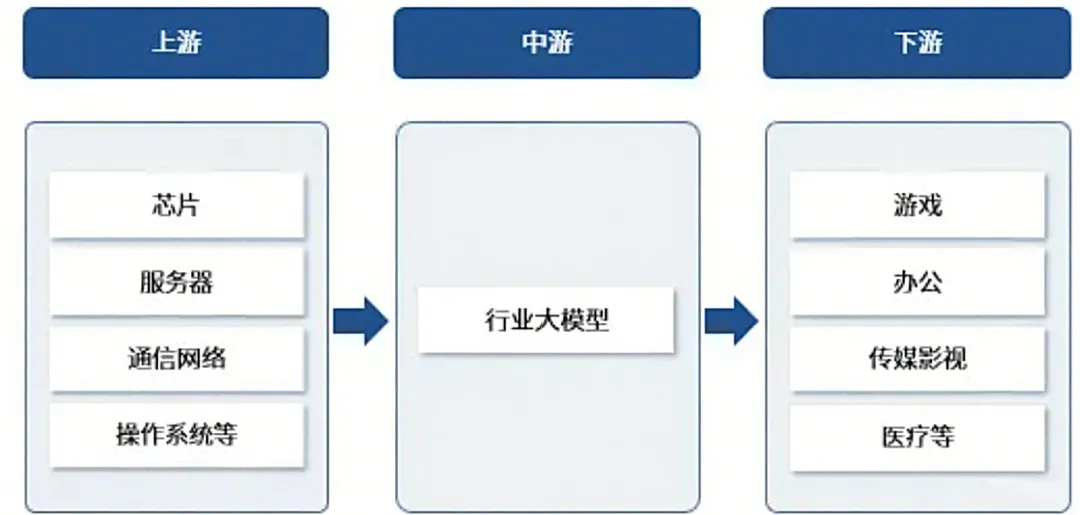
来源:融中咨询
(2)行业市场规模
大模型的市场规模近年来呈现爆发式增长,全球范围内,2024年大模型市场规模超280亿美元,未来五年复合增速将达到36.23%,2028年有望超过1,000亿美元。其中美国占据主导地位,其基础大模型发布数量占比达69%,中国和英国紧随其后[1]。
图8:全球大模型市场规模(亿美元)
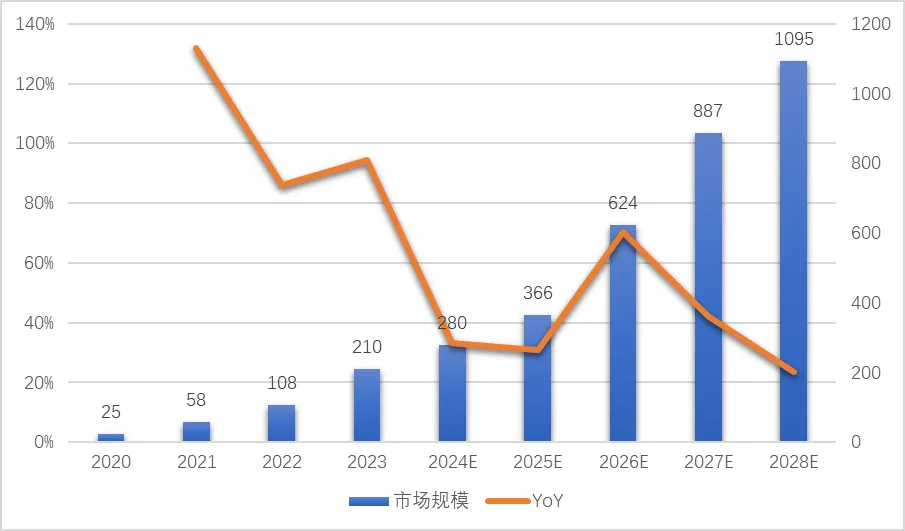
来源:浙商证券研究所
根据我国工信部数据,2023年全年我国语言大模型市场规模实现较快提升,应用场景不断丰富,增长率突破100%,初步统计,2024年中国市场规模超过200亿元,2028年市场规模有望超过1,000亿人民币[1]。
图9:中国大模型市场规模(亿人民币)
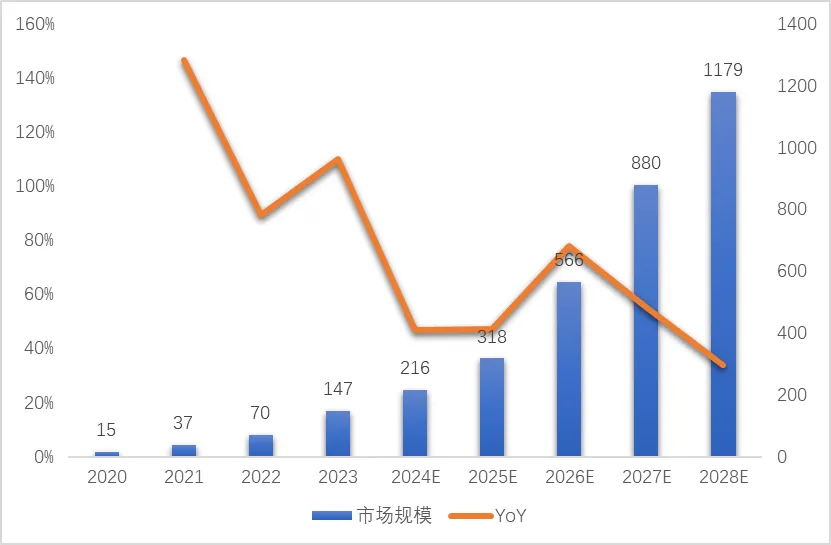
来源:浙商证券研究所
(3)商业模式
大模型的商业模式多样且持续演进,主要包括基于用量的API调用收费、订阅制、广告收入、平台生态模式收取使用费及分成,以及定制化服务(MaaS)等核心形式。
从商业化结构来看,B端变现模式更加清晰,C端大多数产品仍然以免费为主。虽然纯B端市场占比只有31%,但80%以上的产品均能实现营收;纯C端用户占比50%以上,但43%的产品当前仍未有明确的收入模式,以免费为主[2]。
图10:AI应用面向用户群体结构
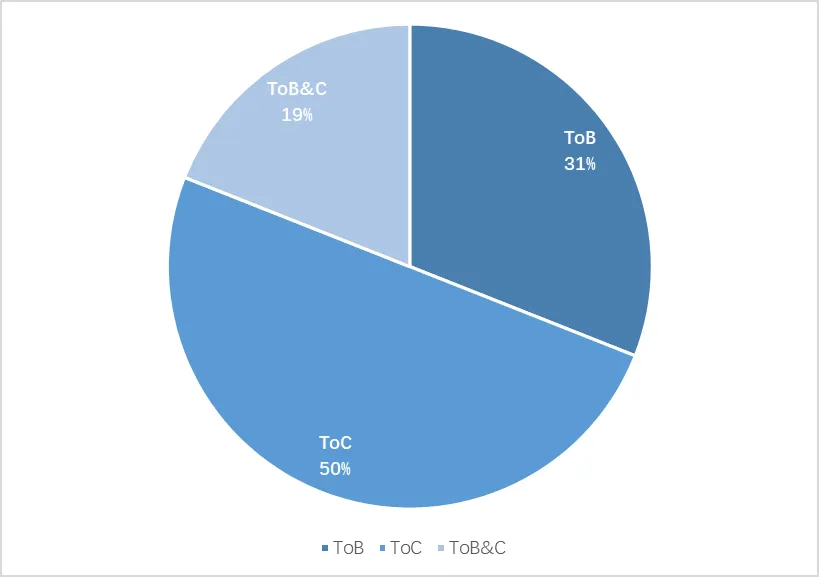
来源:融中咨询
图11:AI应用面向用户收费模式
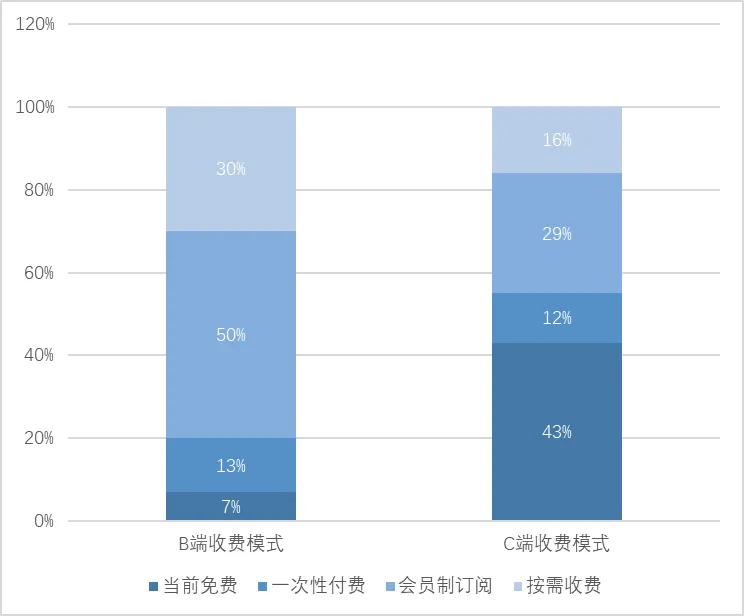
来源:融中咨询
从应用场景来看,当前通用场景中的主流盈利模式是通过API调用按Tokens、调用次数或时间区间计费;C端产品常见订阅制,大模型应用如智能助手类App也常见广告盈利;与第三方开发者通常通过平台生态模式收费及分成。未来,MaaS定制化服务预计成为主流,推动行业向头部厂商收敛。
应用落地情况
(1)大模型应用落地情况现状
目前,各行业在大模型技术的应用上主要集中在两个阶段:探索孵化期与试验加速期。部分行业已经步入采纳成长期,尚未有行业达到落地成熟期。
图12:主要行业的大模型应用阶段情况示意图
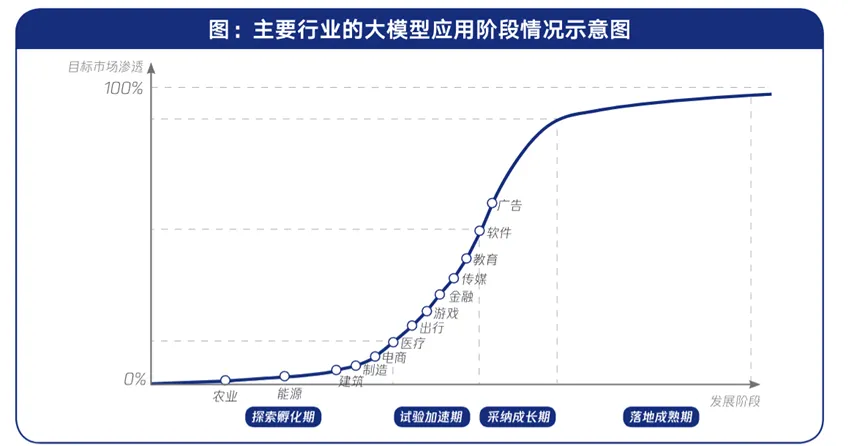
来源:腾讯研究院
截至2023年,金融、政府、影视游戏和教育领域是大模型渗透率最高的四大行业,渗透率均超过50%。电信、电子商务和建筑领域的应用成熟度较高。
图13:大模型渗透率和应用成熟度示意图
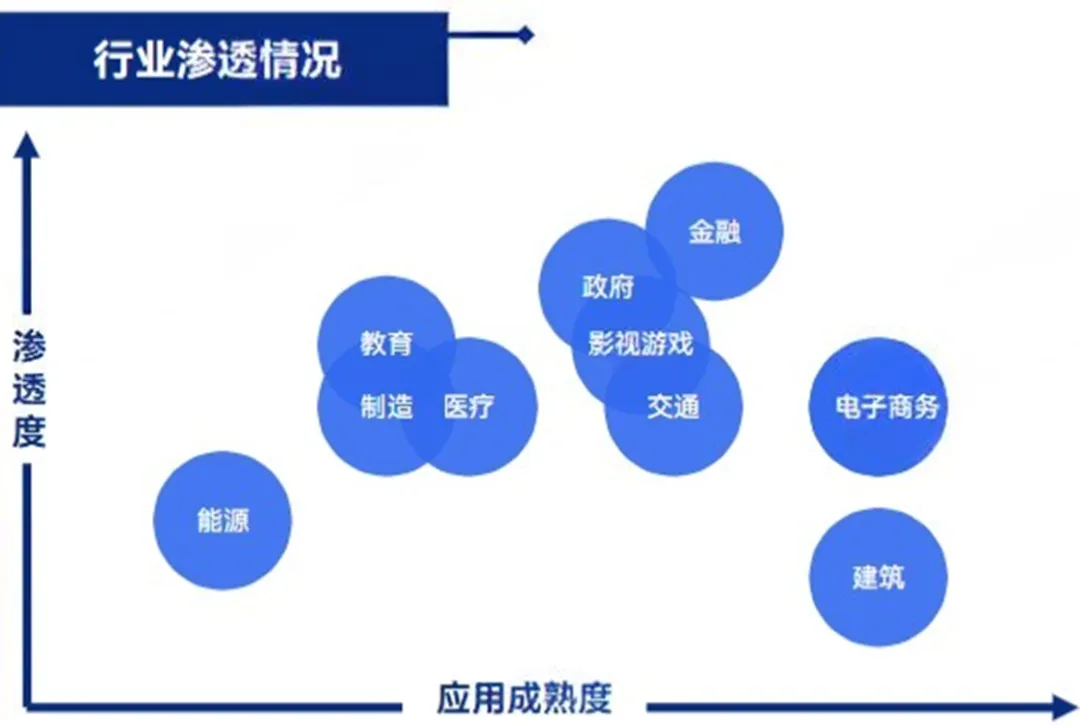
来源:融中咨询
应用场景呈现“微笑曲线”特征,产业链高附加值的研发设计与营销服务环节进展最快。而在低附加价值的中部(生产、组装等),大模型应用进程较慢。
图14:大模型应用场景“微笑曲线”
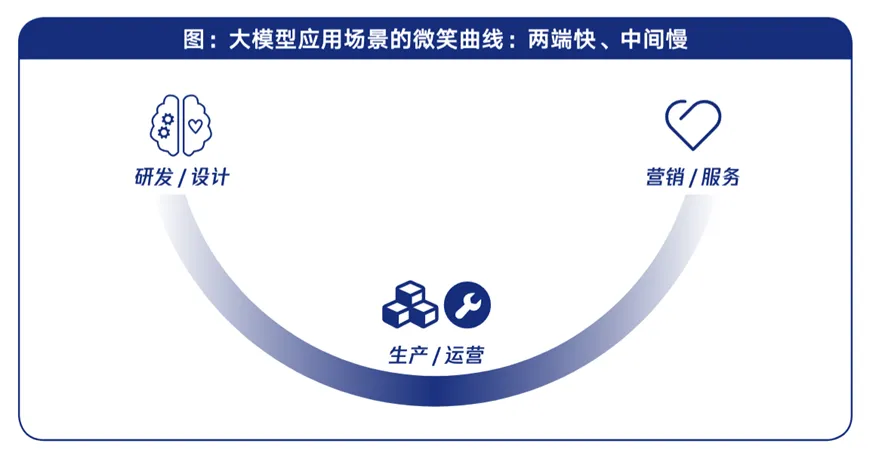
来源:腾讯研究院
表2:大模型应用场景代表
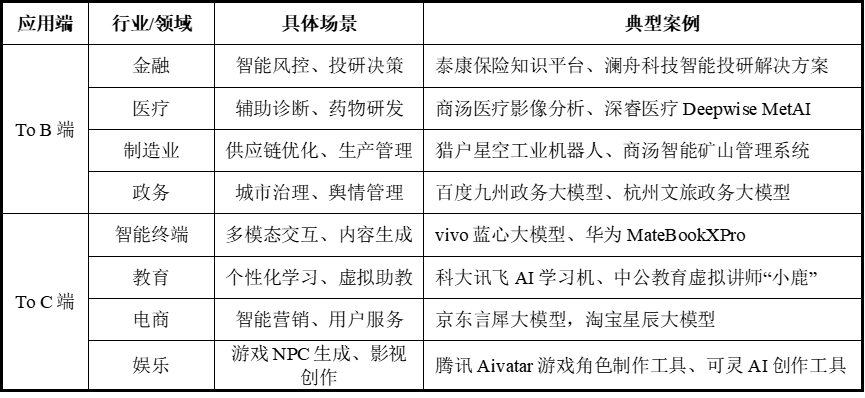
来源:融中咨询
竞争格局
(1)全球竞争格局
从全球范围来看,美国、中国及欧洲在大模型领域引领全球发展。在2024年的重要大模型(Notable Models)评估中,美国以40个模型的入选数量领先,而中国则以15个位列第二,欧洲以3个模型排名第三。在业内顶级专家评选出的32项“2024年AI领域重要发布”中,中国的阿里Qwen2、Qwen2.5及DeepSeek-V3发布上榜[3]。
图15:全球重要大模型分布
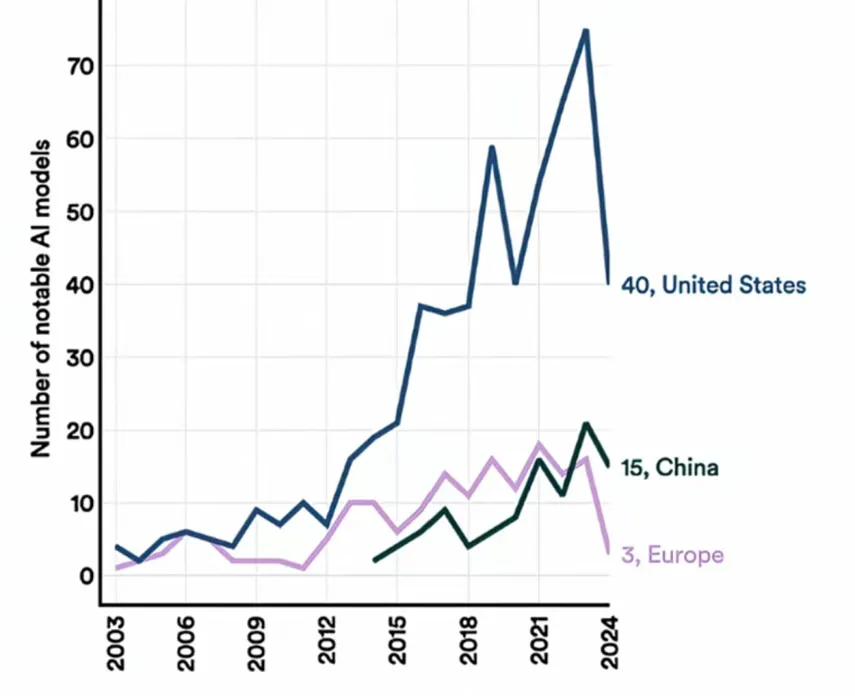
来源:Epoch AI
此外,斯坦福大学发布的《2025年人工智能指数报告》报告显示,中国大模型性能提升显著,由2023年的17.5%大幅缩至0.3%,中美双方的模型性能差距逐渐缩小。2024年1月,美国最佳模型的表现较中国顶尖模型领先9.26%;到2025年2月,这一差距已缩小至1.70%。在推理、数学和编程等其他基准测试中,也可观察到类似趋势。
图16:中美大模型对比(LMSYS)
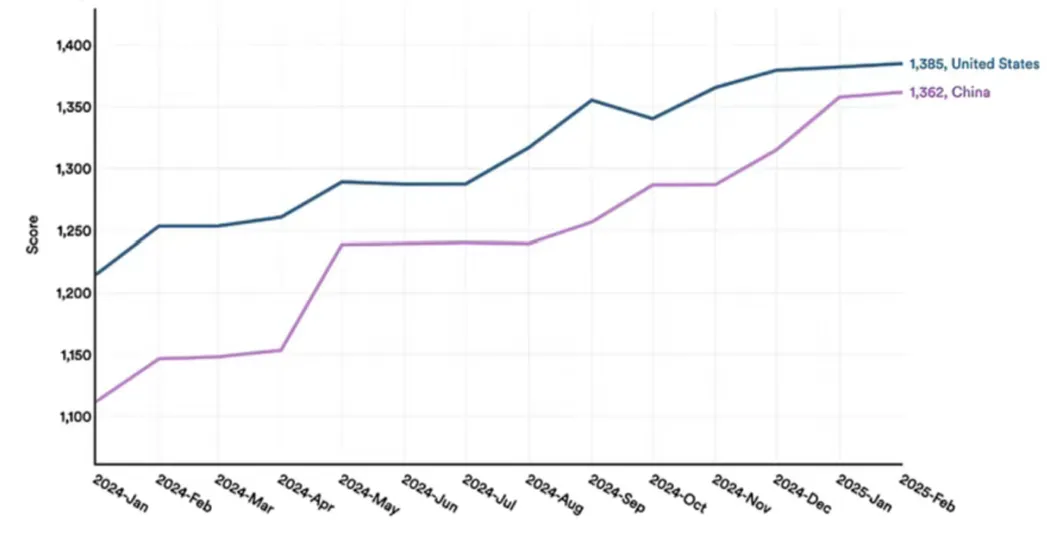
来源:LMSYS
从海外大模型格局来看,OpenAI、Anthropic、谷歌三大厂商领头闭源大模型,Meta开源追赶的格局。OpenAI凭借2023年先发的GPT-4,基本稳定在行业龙头地位,而Anthropic凭借Claude、谷歌凭借Gemini后发。可以看到,2024年以来,三家大模型能力呈现互相追赶态势。
表3:OpenAl 、Google 、Anthropic 主要模型对比
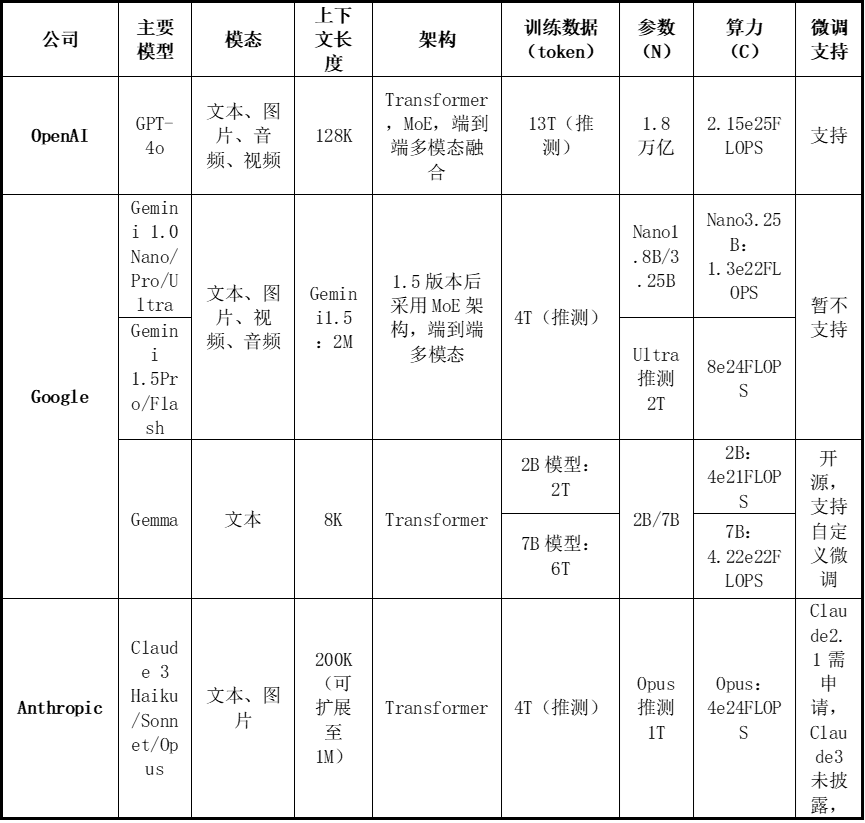
来源:各公司官网、华泰研究
OpenAI:于2025年4月最新发布的o3和o4-mini模型是OpenAI首批具备“图像思考”能力的模型。与谷歌Gemini2.5 Pro和Anthropic Claude 3.7 Sonnet相比,o3和o4-mini的图像分析能力更接近人类水平,能处理模糊、低质量图像,并在推理中动态调整画面。
Anthropic:于2025年5月发布最新大模型ClaudeOpus4和ClaudeSonnet4。据日本Rakuten测试数据显示,基于Opus4打造的编程智能体,可独立稳定连续工作7小时,超越此前OpenAI的纪录;Sonnet4在编程领域的SWE-bench测试中得分达到72.7%,超过了OpenAI最新发布的Codex-1、o3等前沿模型[4]。
谷歌:于2025年5月推出最新模型Gemini2.5Pro,其特点在于,不仅整体领先,且表现均衡,没有明显弱项。在几乎所有的评测维度上都稳居第一,尤其是在理解并执行带风格要求的复杂指令及维持多轮对话连贯性方面优势显著。
图17:Gemini2.5Pro登顶LMSYS Arena榜单
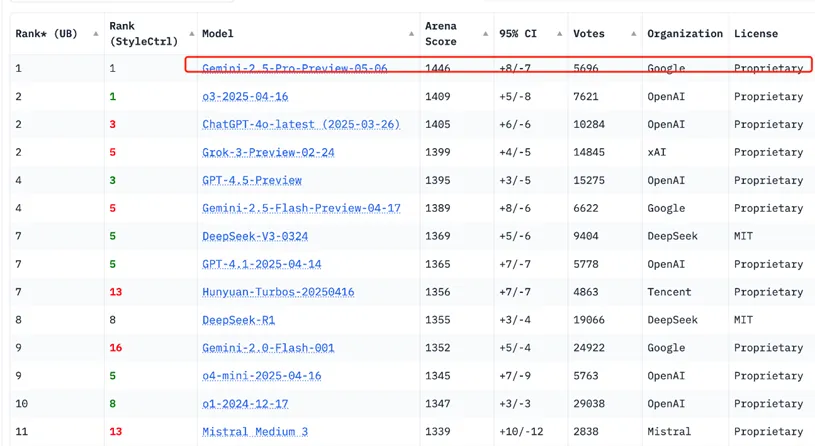
来源:LMSYS Arena
开源模型中,Meta在格局上具有特殊的分界性。
Meta于2025年4月推出最新模型Llama4,海外模型厂商如果在性能上无法超越同代的开源Llama,就很难在海外基础模型中占据一席之地。反之,如果能够超过同代的Llama或者有独特使用体验,则易得到用户青睐,例如具有差异化应用场景的陪伴类应用Character.ai、拥有独家平台数据库的xAI的Grok-1、Grok-1.5。
图18:Meta在海外大模型市场格局的特殊性
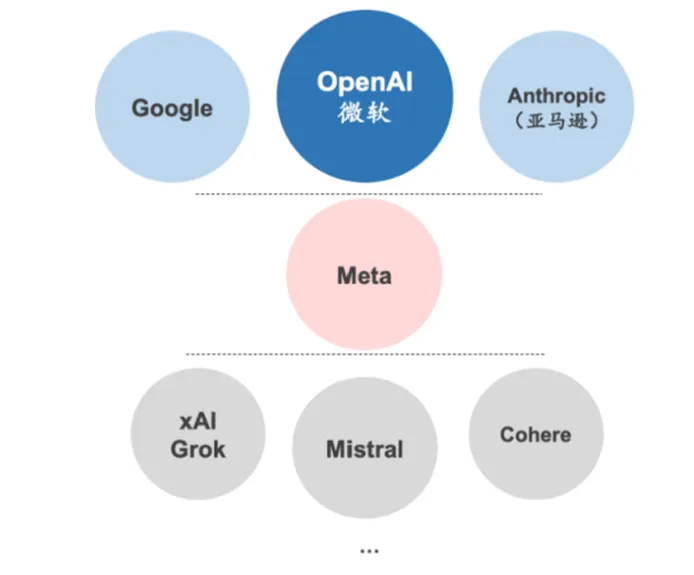
来源:各公司官网、华泰研究
(2)中国竞争格局
目前国内大模型仍处研发和迭代的快速发展阶段,互联网巨头、初创公司、科技企业均有代表性模型产品,形成“巨头引领、初创突围”的双轨格局。
互联网巨头以阿里巴巴、腾讯、字节跳动等为代表,依托固有业务更早形成壁垒;创业梯队形成“6+2”格局,包括“创业六小强”——智谱AI、MiniMax、阶跃星辰、百川智能、月之暗面和零一万物,以及面壁智能和DeepSeek两家新起之秀。
核心功能上,处理文本功能相对突出的有阿里通义千问、智谱AI、百度文心一言、月之暗面Kimi 、百川智能等;具备多模态相对优势的有Minimax、豆包、阶跃星辰、腾讯混元、紫东太初等;在逻辑推理功能比较突出的有DeepSeek、科大讯飞星火大模型、昆仑万维、华为等。
策略上,阿里巴巴通义千问、DeepSeek、昆仑万维、中科院紫东太初等主要布局开源策略,通过开源建立开发者社区,实现快速生态扩张;华为、字节跳动豆包、月之暗面Kimi等主要布局闭源策略,确保技术垄断、数据安全及商业化可控;腾讯混元、智谱AI、科大讯飞星火大模型、面壁智能、阶跃星辰、百川智能、Minimax、零一万物等则选择混合策略,平衡开源引流与闭源变现。
区域分布中,北京绝对领先,聚集智谱AI、百川智能、字节跳动等大模型数量占全国40%;广东凭借华为盘古、腾讯混元等32个人工智能大模型形成生态矩阵,侧重金融、制造等场景应用落地,截至24年3月,综合算力指数全国第一;浙江(阿里)、上海(阶跃星辰)紧随其后。其他省份如安徽(科大讯飞)、四川(华为云)、江苏(云从科技)等主要依托单一龙头企业布局。
图19:我国AI大模型产业重点企业分布图
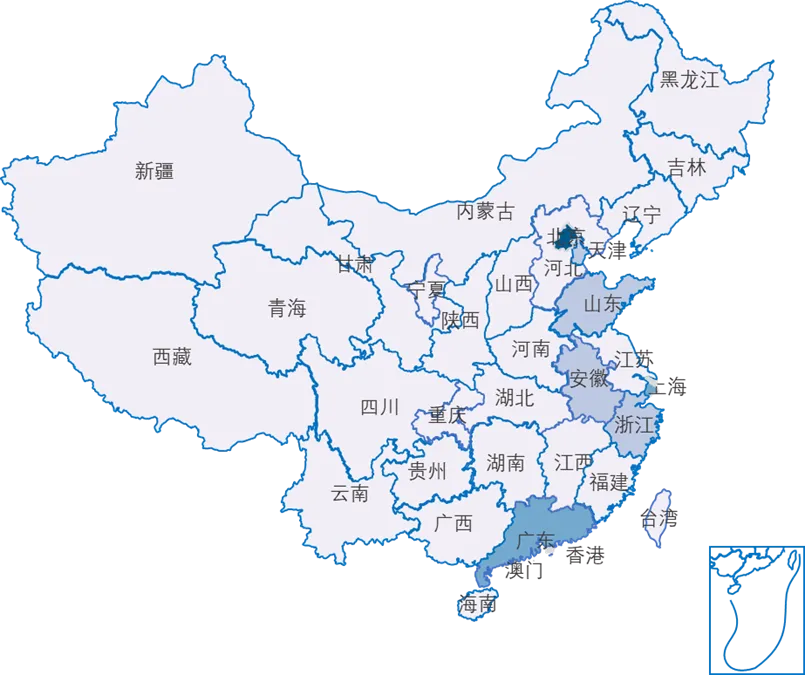
来源:融中咨询
企业分析
(1)互联网科技巨头
1)百度:文心大模型
百度自2010年起就布局人工智能,现已实现全栈AI闭环,覆盖芯片层(昆仑芯片)、框架层(飞桨深度学习平台)、模型层(文心大模型系列)、应用层,且在各层都有相对领先的关键自研技术。
“文心”大模型包含NLP大模型、CV大模型、跨模态大模型、生物计算大模型、行业大模型等,分别可用于语言、图像、跨模态、生物、细分行业等。其中,“文心一言”是基于文心NLP大模型的对话式产品,能够与人对话互动、回答问题、协助创作,其核心优势是对中文的理解。截至2024年底,“文心一言”用户规模达到4.3亿。百度于2025年3月发布“文心”大模型4.5和X1,4.5是原生多模态大模型,多模态理解和生成能力强,测试成绩优于GPT4.5,API调用价格仅为其1%。X1是深度思考模型,增加多模态和多工具调用,性能对标DeepSeek-R1,调用价格为其一半。
图20:文心全景图
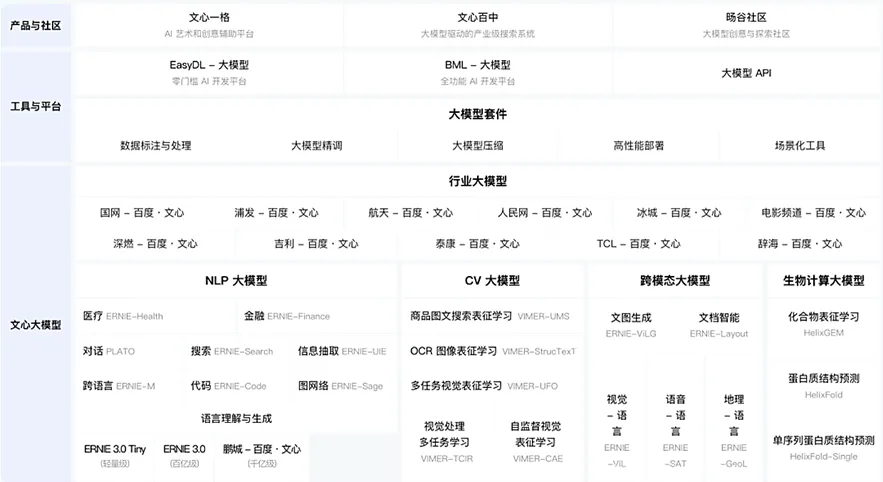
来源:文心大模型官网
2) 阿里:通义大模型
阿里是全球少有实现“全尺寸、全模态”开源的云计算厂商。截至25年5月,已开源200+模型,衍生模型超10万,下载量突破2亿次,Hugging Face社区占比超30%。但是非阿里云用户需额外采购云资源,削弱了其开放性。
通过“通义”大模型,阿里构建了层次化的模型体系,其中通用模型层覆盖自然语言处理(通义千问)、多模态等,专业模型层则深入医疗、法律、金融、娱乐等行业。2025年4月,阿里发布的Qwen3是国内首个混合推理模型,其参数量仅为DeepSeek-R1的1/3,但成本大幅下降,性能全面比肩R1、OpenAI-o1等全球顶尖模型。
图21:阿里通义大模型架构
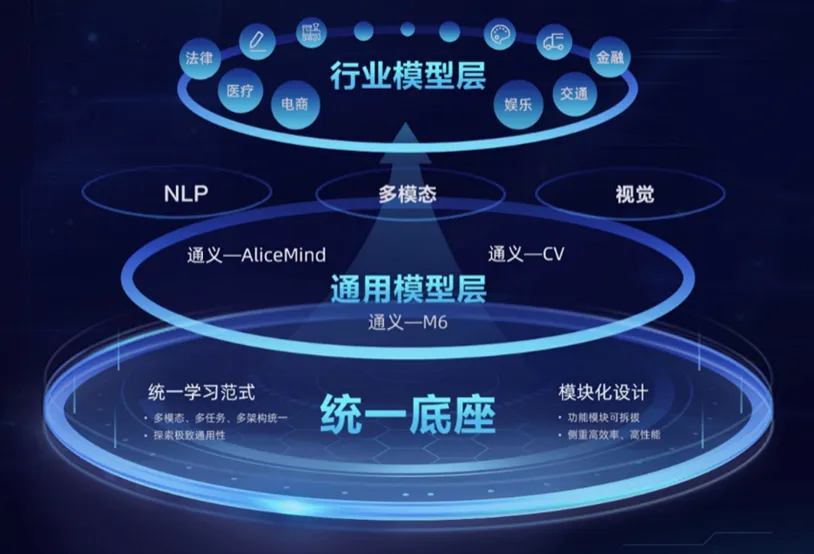
来源:阿里巴巴
3) 腾讯:混元大模型
腾讯的“混元”大模型涵盖计算机视觉、自然语言处理、多模态内容理解、文案生成、文生视频等方向。
“混元”大模型在社交、娱乐等垂直领域具有独特优势。依托微信、QQ、等超级App积累的社交关系链、用户画像及内容交互数据,“混元”大模型在个性化推荐、情感交互、UGC内容生成方面的能力具备一定不可替代性。此外,“混元”大模型依托腾讯游戏、腾讯影业、阅文集团,实现了在游戏与泛娱乐场景的垂直突破。
2025年2月,腾讯最新发布的“混元TurboS”是业界首款大规模混合Mamba-MoE模型,在Chatbot Arena上国内仅次于DeepSeek。基于TurboS基座,腾讯随之推出视觉深度推理模型T1-Vision和端到端语音通话模型混元Voice。T1-Vision实现“边看图边思考,Voice实现低延迟语音通话,拟人性和情绪应用能力也有明显提升。
图22:腾讯混元TurboS位列Chatbot Arena 榜单第八
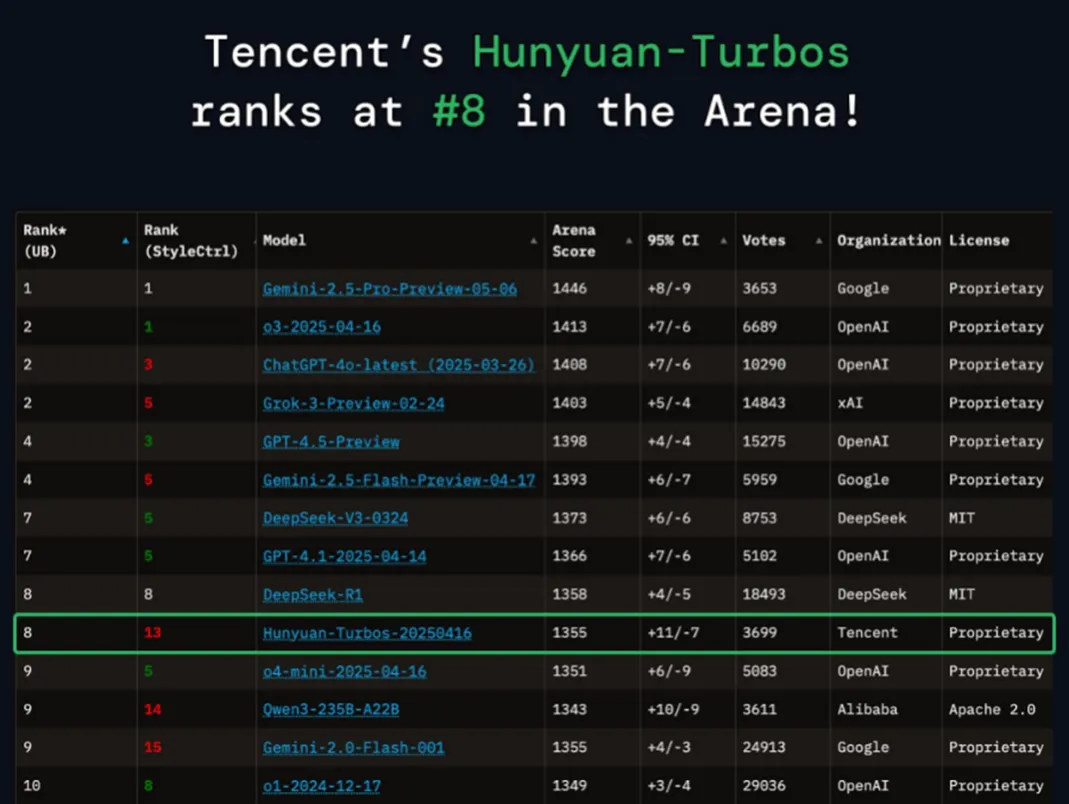
来源:Chatbot Arena
4)华为:盘古大模型
华为构建了强大的AI技术生态系统,包括“鲲鹏+昇腾”算力资源、Mind Spore AI框架、Model Arts开发平台和盘古大模型四层架构。其中,华为“盘古”大模型由计算机视觉大模型、科学计算大模型、自然语言处理(NLP)大模型、多模态大模型组成。2025年4月,华为最新发布的Pangu Ultra是基于昇腾算力的千亿级通用语言大模型,证明了基于全国产也可以实现领先的大规模语言模型的研究与开发。
“盘古”大模型更强调行业应用,而非泛化场景,通过“5+N+X”分层架构,联合打造行业解决方案。例如,盘古CV大模型目前覆盖了工业质检、物流仓库监控、时尚辅助设计等领域;盘古NLP大模型覆盖了智能文档检索、智能ERP和小语种大模型;盘古科学计算大模型则应用于气象预报、海浪预测等方面。
表4:盘古系列模型应用场景和领域
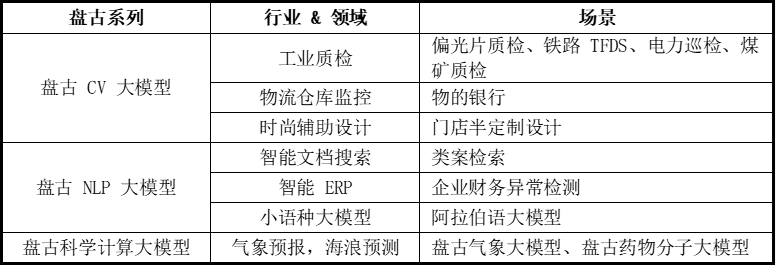
来源:华为,国信证券经济研究院
5)字节:豆包大模型
字节的“豆包”大模型家族涵盖9个模型,主要包括通用模型pro、通用模型lite、语音识别模型、语音合成模型、文生图模型等,侧重于在语言大模型和图像大模型两方面布局。字节最新推出的Doubao-1.5-realtime-voice-pro实现会哭会笑、能说方言会唱歌的多模态能力的全面提升。
“豆包”大模型在多模型功能、短视频领域具有显著优势,但“豆包”在长文本与逻辑推理上相对较弱。依托抖音、TikTok、今日头条等超级App,“豆包”大模型在短视频理解、实时热点捕捉、多模态内容生成上具备数据壁垒;通过用户点击、停留、互动数据,“豆包”模型能精准预测内容传播趋势对短视频帧级语义分析。并且依托TikTok的全球流量,将有助于“豆包”加速海外市场布局。
6) 科大讯飞:星火系列大模型
科大讯飞的“星火”系列大模型是国内首个完全基于国产算力训练的大模型,初代发布于2023年5月,至今已迭代至星火V4.0。2025年4月,科大讯飞最新推出首个基于全国产算力训练的深度推理大模型“讯飞星火X1”,在模型参数比同类模型小一个量级的情况下,整体效果对标OpenAIo1和DeepSeekR1;同时,支持SFT、强化学习两种模型定制优化方案,定制门槛低。
“星火”大模型深耕教育和医疗方向,同时通过行业定制化解决方案赋能汽车、办公等多个垂直领域。依托讯飞智慧教学平台,其AI学习机覆盖全国2000余所学校,智能批阅机和教师助手提升教学效率,偏远地区1000多所学校受益于AI教育公益项目;依托讯飞医疗,智医助理在6万家基层医疗机构应用,提供超8.77亿次辅诊建议,修正150万例诊断。
(2)典型大模型创业企业
1) 深度求索:DeepSeek系列大模型
2025年1月,深度求索“DeepSeek-R1”的发布引燃生成式AI行业热情。作为开源模型,DeepSeek创新探索“算法优化替代算力堆砌”的路径,它的成本大幅低于其他模型,同时性能与OpenAI等先进闭源大模型接近。截至2025年3月末,已有超100家金融机构完成DeepSeek本地接入或部署,涵盖银行、证券、保险等主要金融业态。
DeepSeek通过开源带来的模型平权推动相关企业加速适配DeepSeek。2025年2月以来,已有超20家云服务和智算企业宣布支持DeepSeek,包括华为云、腾讯云、阿里云、百度智能云、火山引擎、京东云、三大运营商云等。同时,海外科技巨头微软、英伟达、英特尔、亚马逊等也已上线DeepSeek。
(2) 智谱AI:GLM系列模型
智谱AI成立于2019年,其研发的GLM系列模型创新性地结合了GPT和BERT的架构优势。2021年3月,智谱成为国内首个完成千亿参数模型训练的公司,比百度ERNIE 3.0早4个月。2025年3月,智谱AI推出将深度思考与自主行动结合的“AutoGLM沉思”模型,其特点在于,“AutoGLM沉思”不仅能深入研究、提供分析,还能主动执行任务,推动AIAgent从单纯的思考者进化为能够交付结果的智能执行者。
智谱团队兼具商业化运营能力,开创了“模型即服务(MaaS)+智能体生态”的双轮模式。“AutoGLM沉思”智能体上线三个月,已为2万家中小企业自动生成上市招股书、尽调报告等专业文档,客单价达3万元/年。而开源的ChatGLM系列,则通过开发者生态衍生出超过200个垂直行业插件,形成独特的"开源获客,闭源变现"路径。不过,智谱AI在多模态生成及C端市场开拓稍显不足:视频生成功能“清影”初步研发,与Sora、Pika等国际模型存在差距;C端业务目前以免费为主,主力应用“智谱清言”,与国内主流大模型日活跃量相比差距较大。
图23:AutoGLM沉思背后的GLM模型架构

来源:CSDN社区
(3)月之暗面:Kimi
月之暗面(Moonshot AI)成立于2023年3月,核心产品是23年10月推出的智能助手产品Kimi。Kimi专注于长文本处理,支持200万汉字的无损上下文输入,远超当时Claude-100k(实测约8万字)和GPT-4-32k(实测约2.5万字)。截至2024年末,Kimi全平台月活跃用户达2,101万,全年复合增长率69.4%23。不过,Kimi面临巨头生态挤压困境。通义千问、360AI浏览器先后宣布将支持1000万、500万字的长文本功能,文心一言将开放长文本能力,文字范围会在200万至500万字。
自2024年12月起,Kimi连续发布一系列模型并开源Kimi-VL视觉语言模型及Kimina-Prover技术报告。其中,k1.5short-CoT在数学、代码、视觉多模态和通用能力,大幅超越了GPT-4o和Claude 3.5 Sonnet。
图24:k1.5 short-CoT在数学、代码、视觉多模态和通用能力的表现
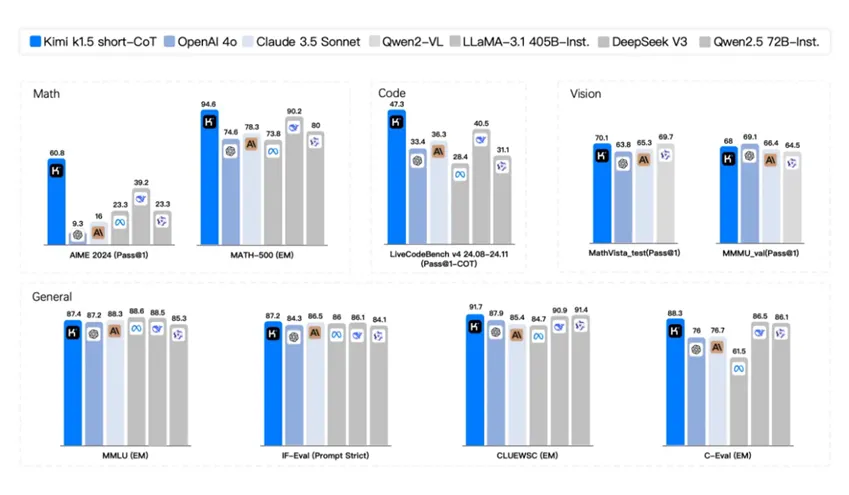
来源:AIME,MATH500,Codeforces,LiveCodeBench,MathVista,MMMU等各榜单
(4) 百川智能:Baichuan大模型
百川智能是由前搜狗CEO王小川于2023年4月创立,成立后相继发布了Baichuan-7B、Baichuan-13B等开源模型及Baichuan-53B、Baichuan2-192K等闭源模型。2024年5月,百川智能发布最新一代基座大模型Baichuan4,较上一代模型通用能力提升超过10%,数学和代码能力分别提升14%和9%。
百川智能是国内少有的专注医疗的头部大模型公司,其构建了超千亿Token的医疗数据集,通用医疗增强大模型不仅在USMLE测试中超越了GPT-4,并且在协和、北医等头部医疗机构进行的人工测评中超越了GPT-4。2024年8月,百川智能与北京儿童医院签署战略合作协议,共同推出五款AI医疗产品。
图25:Baichuan4在SuperCLUE2024年4月榜单国内第一
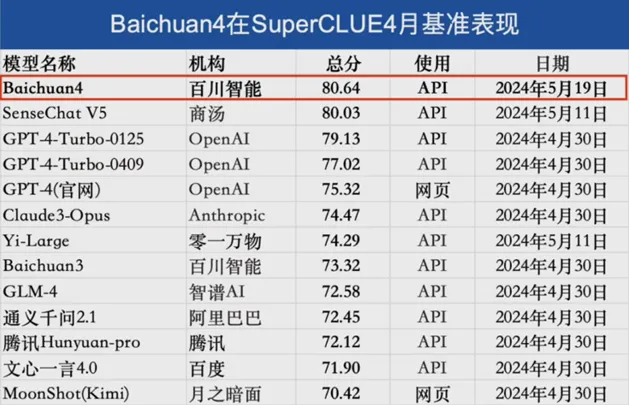
来源:SuperCLUE
(5) 昆仑万维:天工大模型
昆仑万维在2020年便已开始布局AIGC领域,形成了AI大模型、AI搜索、AI游戏、AI音乐、AI动漫、AI社交六大AI业务矩阵。以AI音乐平台Mureka、AI短剧产品SkyReels、AI社交产品Linky为代表,昆仑万维在不断拓展差异化AIGC娱乐场景边界。
昆仑万维的“天工”大模型在国际化及娱乐垂直领域具有较强优势。昆仑万维2024年海外业务营收16.7亿元,占总收入比重达94.9%。2025年5月,昆仑万维正式推出全球首款基于AI Agent架构的Office智能体手机应用“天工超级智能体”。该模型具有较强的自主决策能力,例如当用户输入“撰写行业报告”时,系统能自动调用权威数据库进行交叉验证,生成完整框架,并同步生成PPT与Excel。
图26:昆仑万维在GAIA评测登顶全球榜首
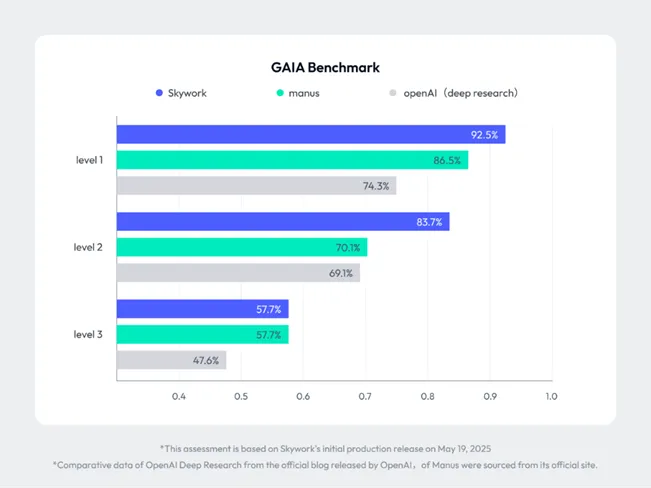
来源:GAIA
(6)MiniMax:abab系列大模型
MiniMax成立于2021年11月,相较于同业往往以某一模态为主,MiniMax较早布局多模态领域,目前已推出视频大模型、音乐大模型及语音大模型,围绕产品需求打造全矩阵多模态模型。abab-video-1支持1280×720 分辨率、25fps的高清视频生成,具备电影感镜头移动效果,在物理正确性、动态稳定性和风格多样性上达到实用水准。abab-speech-1情绪表达细腻自然,与视频生成模型结合可实现多语言视频配音。
2024年,MiniMax发布万亿参数MoE架构模型。2025年1月,MiniMax发布并开源新一代01全新系列模型,首次大规模实现线性注意力机制,替代了传统Transformer架构。
图27:MoE与Dense架构对比
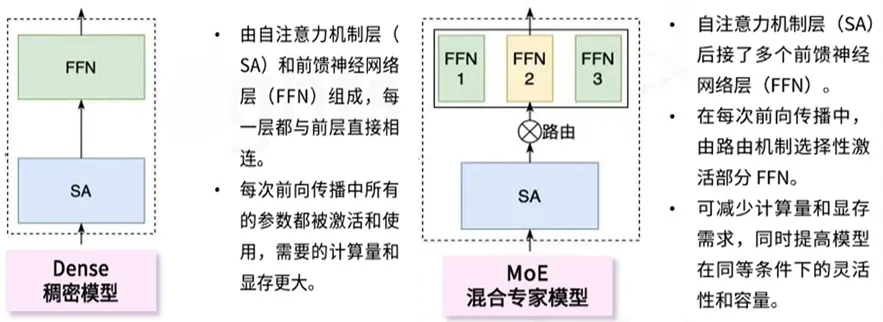
来源:MiniMax
(7)阶跃星辰:Step系列大模型
阶跃星辰成立于2023年4月,其Step系列模型矩阵,包括Step-1千亿参数语言大模型、Step-1V千亿参数多模态大模型以及Step-2万亿参数MoE语言大模型。Step系列在2025年最新发布的模型涵盖视频生成、推理、音乐、3D建模等多个领域。
与MiniMax侧重C端消费者场景不同,阶跃星辰主要提供B端企业级服务,向汽车、金融、智能终端等行业渗透。2024年,阶跃星辰联合国泰君安、界面财联社推出业内首个千亿级参数多模态证券垂直类大模型君弘灵犀大模型,同年与OPPO、TCL合作,将多模态能力嵌入手机、IoT设备。
(8) 面壁智能:MiniCPM系列模型
面壁智能成立于2022年8月,在端侧小模型领域表现突出,其MiniCPM系列模型轻量化与高性能并存。最新模型MiniCPM 3.0量化后可在端侧设备上运行,并实现GPT-3.5级性能,而参数仅为其1/43;
面壁智能坚持开源战略,其模型在GitHub、HuggingFace等平台广受认可,下载量超400万,位列2024年最受欢迎中国企业榜首。面壁智能业务覆盖汽车、智能家居、教育等多个领域,推出AgentVerse、ChatDev等智能体平台。端侧商业化方面,发布全球首个落地车端的纯端侧智能助手“小钢炮超级助手cpmGO”; 2025年4月,面壁智能与长安马自达合作,实现少有的搭载端侧模型的量产车型落地。
图28:MiniCPM-o2.6多模态能力在各项评测榜单评分
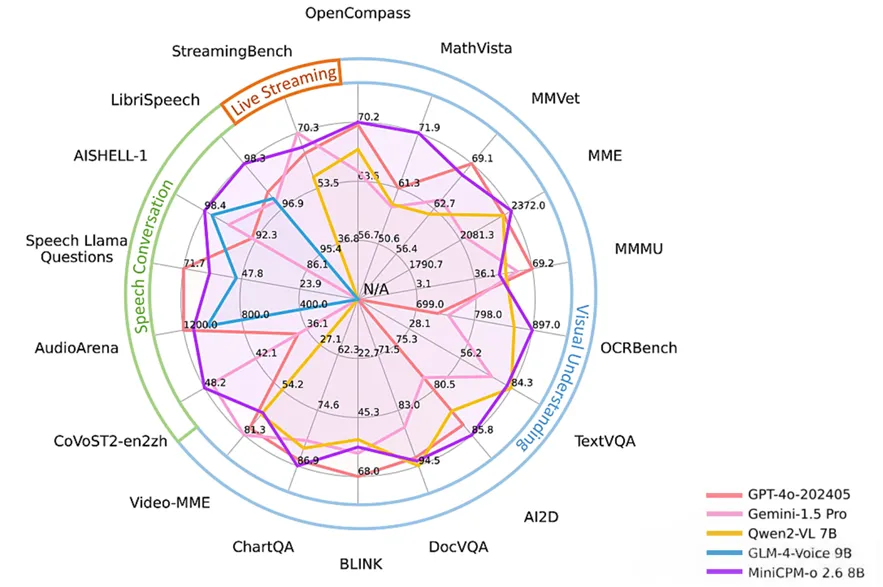
来源:MiniMax
(9)中科院自动化所:紫东太初大模型
“紫东太初”大模型是全球首个支持图文音三模态的大模型。2024年底最新发布的紫东太初3.0,首次从模态独立编码转向多模态统一原生编码,实现“以图生音”等复杂交互,此外,“紫东太初”引入混合专家模型架构,更接近于人类的理解推理和思考能力。
“紫东太初”核心应用集中于政策驱动型场景,政府背书和产学研优势显著。其研发过程得到科技部、工信部等机构的数十项国家重大项目支持,被列为中科院“十四五”规划重点项目。这种定位使其在政策倾斜、行业标准制定、政企协同合作等方面具有天然优势。并且依托国家重点实验室等科研平台,牵头成立多模态人工智能产业联合体,成员单位已达100余家,涵盖高校、企业、科研机构,形成全链条合作生态。但这些项目虽能体现技术价值,市场化拓展能力不足。
风险与挑战
(1)大模型的幻觉
幻觉是指模型生成看似合理但实际上错误或虚假的内容,没有真实依据或与事实相悖,表现形式主要有:编造不存在的人物、事件或数据,张冠李戴、逻辑错误、自相矛盾,“一本正经地胡说八道”等。
幻觉率(Hallucination Rate)是衡量模型生成错误或虚构信息的频率的指标。根据Vectara发布的幻觉评估测试,ChatGPT-4的幻觉率约1-3%,DeepSeek的幻觉率约2-15%,大部分中文大模型的幻觉率在10-30%。
图29:幻觉率最低的25个大模型
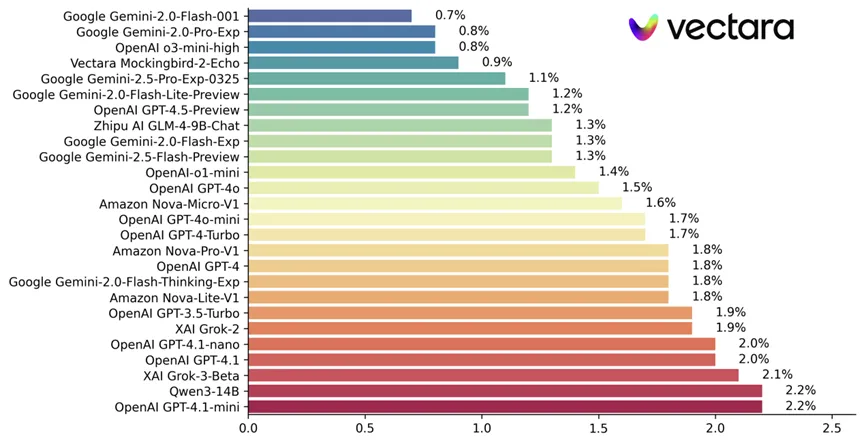
来源:Vectara'sHHEM,更新日期2025年4月29日
(2)算法偏见
算法偏见是大模型在数据驱动学习过程中不可忽视的问题,表现为对性别、种族、文化等的系统性不公,即在处理和生成内容时,有时会系统性偏向某些群体、观点或结果。
算法偏见的主要危害有:加剧社会不平等(如GPT-3生成“女性适合行政岗位”)、侵犯个人权益、引发伦理与法律风险、威胁公共安全与信任、企业声誉与经济损失(如谷歌Gemini因无法正确生成白人历史图像引发公众质疑)等。算法偏见通过数据、算法和应用的连锁反应,放大社会既有不平等,威胁个人权益、企业合规与社会稳定,进而造成公众对AI系统信任的下降。
(3)长上下文限制
大模型在处理超长文本时的能力有限,特别是在输入长度接近或超过其“上下文窗口”限制时,模型要么截断前文,要么压缩摘要,导致无法再准确记忆、理解或推理大量上下文信息。当前主流模型输入长度普遍在64K–128K,如DeepSeek-V3上下文长度约为64K tokens(约5万字)、GPT-4 Turbo约为128K tokens(约 10 万字),而输出长度多数限制在8K–16K。
与推理效率不同,后者已有蒸馏、剪枝、LoRA等工程化方案可缓解,而长上下文处理尚缺乏标准架构和端到端能力方案,已成为新一代基础模型架构创新的关键瓶颈。它也是阻碍B端大模型落地的第一技术难题。文档问答、代码生成、法律咨询、多轮对话、企业知识库等B端关键场景高度依赖长上下文理解能力,而“上下文窗口”限制了大模型在这些高价值应用场景的落地。
(4)Scaling Law撞墙
OpenAI的GPT-3至GPT-4展示了显著的性能提升,但据报道,其下一代模型“Orion”的性能提升幅度有限,尤其在编程等任务上未明显超越前代模型。这表明,尽管投入了更多的计算资源和数据,模型性能的提升已趋于平缓,传统的 Scaling Law 效应开始减弱。
所谓“撞墙”,即指在进一步扩大模型规模(例如从千亿参数扩展到万亿参数)后,性能提升逐渐放缓甚至停滞,投入的算力与成本无法换来预期的性能收益,主要表现为:边际效应递减、基础路径不再有效、技术不确定性提升以及资源与资金浪费。
Scaling Law 撞墙是大模型行业正面临的一种“范式级挑战”,它意味着依赖无限放大模型规模的路线走到了瓶颈,企业必须在效率、结构创新和多模态协同等方面寻找新突破口。
(5)数据版权
大模型训练高度依赖海量的高质量文本、图像、音频等多模态数据,而这类数据往往来源于互联网、数据库或商业内容平台,很多都带有明确或隐含的版权约束。未经授权使用这些内容进行训练,可能侵犯原作者或平台的知识产权,引发法律诉讼和经济赔偿风险。
近年来,全球范围内已有多起AI企业被新闻机构、作家联盟、图片平台(如Getty Images)等起诉,凸显了这一问题的严重性和现实性。
数据版权问题还带来伦理和行业生态方面的挑战。如果大型企业依靠“掠夺式”数据采集建立模型优势,不仅损害内容创作者权益,还可能挤压中小内容平台的生存空间,扭曲数据获取市场的公平性。这要求AI行业在数据使用上建立合规透明的机制,例如加强数据来源披露、推动开放授权数据集建设、制定行业自律规范等,以在技术发展与版权保护之间寻找平衡。
(6)有害输出
大模型可能在生成过程中输出带有歧视、仇恨、暴力、色情、恐怖主义、欺诈等内容,这些有害输出不仅违反法律法规,也可能对用户心理、安全乃至社会舆论造成严重影响。
2024年2月,美国佛罗里达州14岁男孩在与AI聊天机器人互动后不久自杀身亡。几个月来,他一直在一款人工智能应用程序上与一个栩栩如生的《权力的游戏》聊天机器人聊天,而该聊天机器人却向他发送了一条令人毛骨悚然的信息,让他“回家”吧。男孩随后自杀身亡。
监管机构和公众对生成式AI输出的可信度和道德底线越来越关注,一旦模型被证实频繁输出有害信息,不仅会影响用户信任,还可能触发行业性的政策收紧与限制。
[1]浙商证券研究所《科大讯飞深度报告:讯飞星火点亮千行百业》
[2]慧博智能投研《AI大模型行业深度:行业现状、应用情况、产业链及相关公司深度梳理》
[3]斯坦福大学《2025年人工智能指数报告》
[4]https://mp.weixin.qq.com/s/THZiAlQ8UMvoc9ywJslPYQ
第一时间获取股权投资行业新鲜资讯和深度商业分析,请在微信中搜索“融中财经”公众号,或者用手机扫描左侧二维码,即可获得融中财经每日精华内容推送。
1 融中财经原创文章未经授权严禁转载。
2 本站转载的内容,均已获授权,其版权归原作者所有。
3 网站所刊登内容出于传递信息之目的,并不意味赞同其观点、立场或证实其内容真实性。
4 涉企问题举报入口见网页底部或邮件至thecapital@thecapital.com.cn。
5 内容合作、转载、勘误或其他任何问题,请微信联系irongzhong。